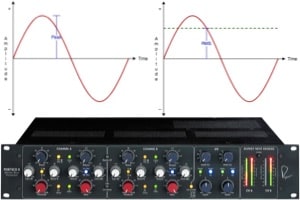
Peak- vs. RMS-Dynamikbereichskompressoren in Audio
Spitzen- und RMS-Werte sind ein heißes Thema in der Audiobranche, daher ist es nicht verwunderlich, dass diese unterschiedlichen Werte auch für die Dynamikbereichskomprimierung gelten.
Was ist Spitzenkompression? Maximale Kompression bedeutet, dass der Kompressor entsprechend der Spitze des Eingangs- oder Sidechain-Signals reagiert. Wenn die Spitze der Kompressorsteuerung den Schwellenwert überschreitet, springt der Kompressor ein.
Was ist RMS-Komprimierung? RMS-Kompression (Root Mean Square) bedeutet, dass der Kompressor entsprechend der „durchschnittlichen Lautstärke“ des Eingangs- oder Sidechain-Signals reagiert. Wenn der „Durchschnitt“ der Kompressorsteuerung den Schwellenwert überschreitet, springt der Kompressor ein.
In diesem Artikel werden wir den Unterschied zwischen Spitzen- und Wurzelmittelwerten diskutieren und wie Kompressoren diese Werte verwenden, um den Dynamikbereich ihrer Eingangssignale zu komprimieren.
Eine Einführung in Audiosignale
Um die Dynamikbereichskomprimierung (und damit sowohl RMS- als auch Peak-Metering-Komprimierung) wirklich zu verstehen, müssen wir die Audiosignale verstehen, die der Komprimierung unterliegen. In diesem Primer-Abschnitt lernen wir die Grundlagen von Audiosignalen kennen.
Audiosignale können als elektrische Energie (aktiv oder potentiell) definiert werden, die Schall darstellt.
Die Wellenformen, aus denen hörbare Schallwellen bestehen, werden effektiv in einem Audiosignal nachgeahmt. Diese Wellenformen haben Spitzen und Täler von maximalen und minimalen Schalldruckpegeln. Schallwellen stören effektiv die Moleküle eines Mediums, während sie sich durch das Medium bewegen.
Der allgemein akzeptierte Bereich des menschlichen Gehörs liegt zwischen 20 Hz und 20.000 Hz.
Audiosignale sind dann weitgehend innerhalb derselben Grenze von 20 Hz – 20 kHz definiert (obwohl Signale Frequenzen jenseits dieses Bandes haben können).
Analoge Audiosignale sind definiert als Wechselstromsignale mit einer Amplitude, die durch die Spannungspegel des Signals definiert wird. Diese Amplituden können in Volt (V) oder Millivolt (mV) angegeben werden. Sie können auch als Dezibel relativ zu 0 Volt (dBV) oder Dezibel relativ zu 0,775 Volt (dBu) angegeben werden.
Ein analoges Audiosignal kann durch folgende 1 kHz Sinuswelle dargestellt werden:
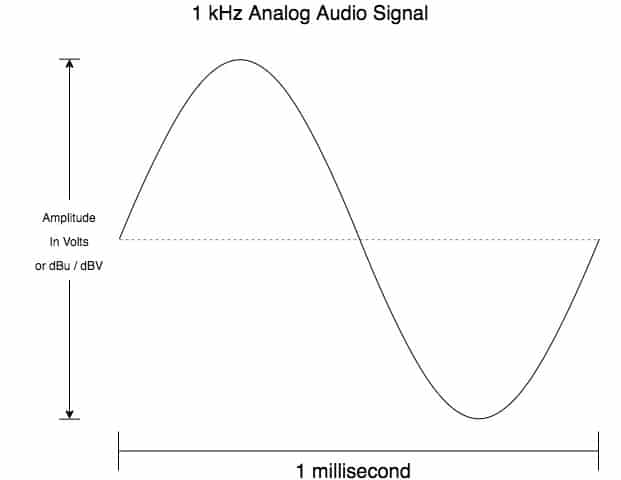
Die Amplituden analoger Audiosignale variieren stark je nach Gerät. Zum Beispiel können Mikrofone nur relativ kleine „Mikrofonpegelsignale“ verarbeiten, während Lautsprecher viel größere Signale benötigen, um ihre Treiber anzutreiben. Die verschiedenen Nennsignalpegel sind in der folgenden Tabelle aufgeführt:
| Signalpegeltyp | Typischer Nennsignalpegel |
|---|---|
| Mikrofonpegel | -60 dBV (1 mV)Rms) bis -20 dBV (100 mV)Rms) |
| Leitungsebene (Verbraucher) | -10 dBV (316 mV)Rms) |
| Leitungsebene (professionell) | +4 dBu (1.228 V)Rms) |
| Instrumentenfüllstand | -20 dBu (77,5 mV)Rms) |
| Lautsprecherebene | 20 dBV (10 V)Rms) bis 40 dBV (100 V)Rms) |
Mixing und Mastering (zusammen mit Audiospeicherung) wird praktisch immer ein Line-Level sein (professioneller Line-Level, idealerweise). Daher liegen die Eingangssignale (und Ausgangssignale) im Allgemeinen bei Kompressoren bei +4dBu.
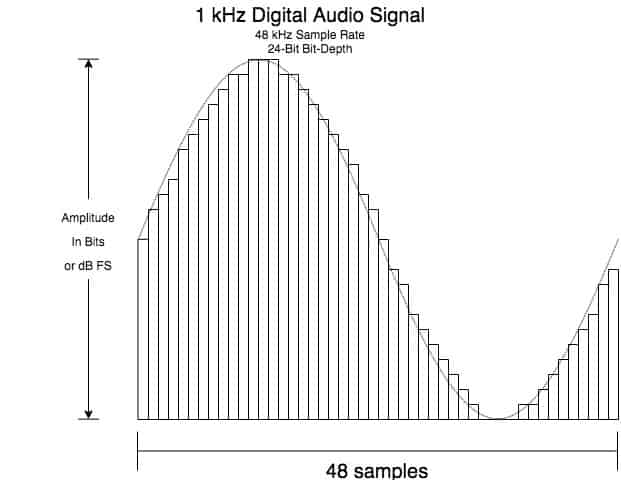
Digitale Signale sind zeitdiskrete Darstellungen ihrer zeitkontinuierlichen analogen Gegenstücke und haben Amplituden/Pegel, die relativ zu einer maximalen Amplitude bei 0 Dezibel (0 dBFS) definiert sind. 0 dBFS ist die absolute maximale Amplitude, basierend auf der Bittiefe, die ein digitales Audiosignal haben kann, bevor digitales Clipping auftritt.
Die oben erwähnte analoge Sinuswelle von 1 kHz in digitaler Form kann mit folgendem Bild visualisiert werden (die digitale Auflösung wird durch eine Abtastrate von 48 kHz und eine Bittiefe von 24 Bit definiert):
In diesem Artikel beschäftigen wir uns mit der Amplitude von Audiosignalen.
Um diese Einführung noch einmal zusammenzufassen:
- Audiosignale sind elektronische Darstellungen (potentielle oder aktive elektrische Energie) von Schallwellen.
- Audiosignale können in analogen (Continuous Time) oder digitalen (Discrete-Time) Formaten gespeichert und wiedergegeben werden.
- Audiosignale werden typischerweise im Frequenzbereich von 20 Hz bis 20.000 Hz definiert, können aber Informationen über dieses Band hinaus enthalten.
- Die Amplitude des analogen Audiosignals wird typischerweise als Wechselspannung, dBV oder dBu definiert.
- Die Amplitude des digitalen Audiosignals wird normalerweise relativ zur maximalen digitalen Amplitude vor dem Clipping (0 dBFS) definiert.
- Kompressoren (und andere Audioprozessoren/Effekte) wirken im Allgemeinen auf Line-Level-Signale.
Jetzt, da wir verstehen, dass Audiosignale haben unterschiedliche Amplituden, wir können Kompression verstehen.
Die ganze Idee der Komprimierung besteht darin, den Dynamikbereich eines Audiosignals zu verringern oder zu „komprimieren“. Der Dynamikbereich ist definiert als der Bereich zwischen der höchsten Amplitude (dem „lautesten“ Teil des Audiosignals) und der niedrigsten Amplitude (dem „leisesten“ Teil des Audiosignals).
Spitzenwerte im Vergleich zu RMS-Werten
Nachdem wir nun verstanden haben, wie Audiosignale durch ihre Amplituden definiert werden und wie Kompressoren den Dynamikbereich von Audiosignalen komprimieren, gehen wir zu unserer Diskussion über Spitzen- und RMS-Werte über.
Bei der Erörterung von Audio beziehen sich Peak und RMS im Allgemeinen immer auf einen Signalpegel. Es könnte sich auf die Leistung, Spannung, dBFS oder andere Einheiten beziehen, die die „Stärke“ eines Signals oder die Fähigkeit eines Geräts definieren, die „Stärke“ eines Signals zu verarbeiten.
Im Falle von Kompressoren gelten diese Bedingungen dafür, wie der Kompressor sein Sidechain-Signal misst.
Die Spitzenamplitude bezieht sich auf den absolut höchsten momentanen Spannungspegel des Signals. Dies kann im folgenden Bild visualisiert werden (ich werde der Einfachheit halber weiterhin Sinuswellen verwenden):
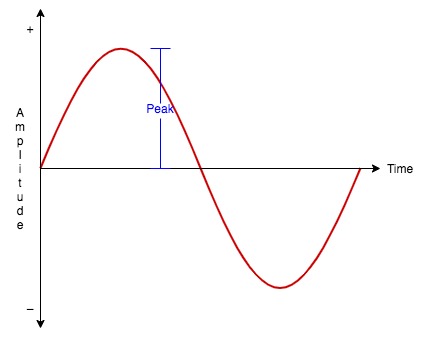
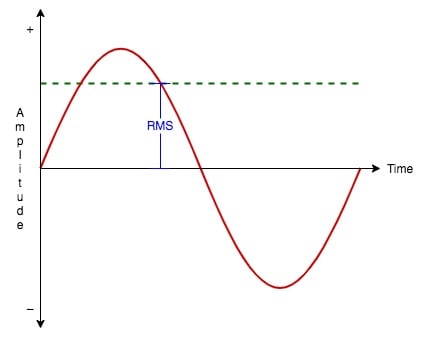
Für einfache Sinuswellen haben wir die folgende Gleichung, um den RMS-Pegel des Signals aus seinem Spitzenpegel zu berechnen.

Was wir am Ende haben, ist VRms = 0,707 VHöhepunkt.
Für komplexere Audiosignale haben wir technisch die folgende, ziemlich komplizierte Gleichung:
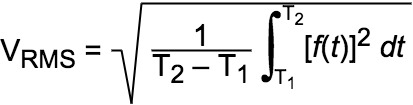
Im Wesentlichen ist RMS-Level-Audio jedoch ein Maß für die durchschnittliche Signalstärke eines bipolaren AC-Signals. Bipolar bedeutet, dass das Signal während seiner gesamten Wellenform sowohl positive als auch negative Amplituden aufweist.
Peak- vs. RMS-Komprimierung
Kommen wir nun zu den Kompressoren. Ein Kompressor kann mit Spitzen- und/oder RMS-Messung ausgelegt sein. Beachten Sie, dass nur ein Messsystem gleichzeitig verwendet werden kann.
Jeder einzelne Kompressor besteht aus zwei Hauptkomponenten:
- Eine Verstärkungsreduzierungsschaltung/ein Element, das das Eingangs-/Programmaudio komprimiert.
- Ein Sidechain-Pfad, der ein Steuersignal (aus dem Programmsignal oder einem externen Signal) erzeugt, das steuert, wie die Verstärkungsreduzierungsschaltung / das Element den Eingang / das Programmaudio dämpft.
Dieses Steuersignal (auch Sidechain genannt) wird vom Eingangsaudiosignal (gemeinsam) oder über ein externes Audiosignal (seltener) abgeleitet. Es kann weiter manipuliert werden, um die typischen Kompressorparameter (Schwellenwert, Verhältnis, Angriffszeit, Auslösezeit, Knie und/oder Ausblick) zu erreichen.
Die Auswahl des Sidechain-Signals kann mit folgendem Signalflussdiagramm eines Feedback-Kompressors visualisiert werden:
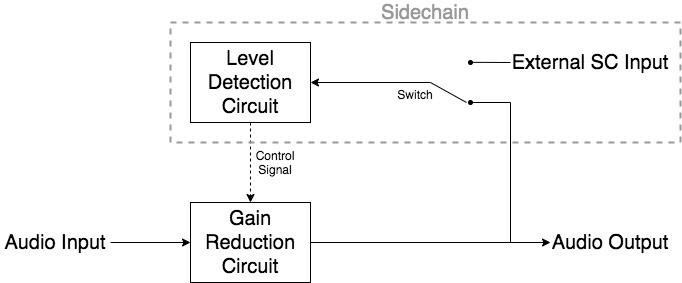
Unabhängig vom Sidechain-Signal muss es eine Füllstandserfassungsschaltung durchlaufen, um in ein Steuersignal für die Verstärkungsreduzierungsschaltung umgewandelt zu werden. Genauer gesagt muss das Sidechain-Audiosignal (AC) gleichgerichtet und in eine DC-Steuerspannung für die GR-Schaltung umgewandelt werden.
Hier kommt die Spitzen- und RMS-Messung ins Spiel.
Die Füllstandserfassungsschaltung eines Spitzenkompressors misst den Spitzenpegel des eingehenden AC-Sidechain-Signals und gibt effektiv eine variierende Gleichspannung aus, die dem Spitzenpegel des eingehenden Signals entspricht.
Umgekehrt misst die Füllstandserfassungsschaltung eines RMS-Kompressors den RMS-Pegel des eingehenden AC-Sidechain-Signals und gibt effektiv eine variierende Gleichspannung aus, die dem RMS-Pegel des eingehenden Signals entspricht.
Glücklicherweise entspricht der RMS eines AC-Signals dem DC-Signalpegel, der die gleiche durchschnittliche Leistung liefern würde, so dass es relativ einfach ist, RMS-Pegel zu erkennen / zu korrigieren.
Die genauen Komponenten und das Layout, aus denen beide Füllstandserfassungskreise bestehen, variieren von Kompressor zu Kompressor.
Aufgrund der Art von RMS und Spitzenpegeln reagieren RMS und Peak-Kompressoren unterschiedlich.
Der offensichtlichste Unterschied besteht darin, dass Spitzendetektoren Steuersignale mit höheren Amplituden erzeugen. In Bezug auf das Auslösen des Kompressors benötigt ein Spitzenkompressor einen höheren Schwellenwert als ein RMS, um denselben Triggerpunkt zu erreichen, wenn er mit demselben Sidechain-Audio aufgefordert wird.
Die RMS-Erkennung ist auch langsamer und reagiert nicht so abrupt auf die Änderungen des eingehenden Signalpegels.
Das Fenster eines RMS-Füllstandsdetektors bezieht sich auf die Zeitspanne, die der Detektor in seinem Speicher hält, um den „Durchschnitt“ des Signals zu messen. Kürzere Fenster machen den RMS-Detektor reaktiver, und längere Fenster nehmen den Mittelwert über einen längeren Zeithorizont auf.
Beachten Sie, dass die Fenstergröße nicht mit den Angriffs- und Auslösezeiten des Kompressors übereinstimmt. Beachten Sie auch, dass eine theoretische Fenstergröße von Null den RMS-Detektor effektiv in einen Spitzendetektor verwandeln würde.
Peak-Detektoren können zur Begrenzung verwendet werden, wo schnelle Reaktionszeiten erforderlich sind, um alle Audiosignale zu unterbinden, die die Schwelle überschreiten.
Die RMS-Komprimierung ist oft subtiler und langlebiger (bei gleichen Angriffs-/Auslösezeiten) als die Spitzenkompression, was sie zu einer hervorragenden Wahl für nicht-perkussive Instrumente, Gesang und Mix-Busse macht.
Da sie nur auf die durchschnittliche Amplitude wirkt, kann die RMS-Komprimierung transiente Spitzen in einem Signal möglicherweise vollständig übersehen.
Die Spitzenkompression ist oft auffälliger, was sie bei perkussiven/transienten Signalen nützlich macht. für Pumpeffekte und im richtigen Kontext für die Sidechain-Kompression.
Beispiele für Kompressoren mit Peak- und RMS-Optionen
Bevor wir die Dinge abschließen, ist es immer eine gute Idee, einige Beispiele für Kompressoren zu betrachten, die sowohl Spitzen- als auch RMS-Messoptionen bieten.
Beachten Sie, dass ich bestimmte Begriffe in diesem Abschnitt mit ausführlichen My New Microphone-Artikeln zu den Themen verlinke.
Rupert Neve entwirft Portico II
Das Rupert Neve Designs Portico II Master Buss Compressor (Link zum Preis bei B&H Photo/Video) ist ein Stereo-VCA-Kompressor. Jeder der Kanäle (A & B) verfügt über eine Drucktaste, um zwischen RMS und Peak Metering zu wählen.

Wie der Name schon sagt, funktioniert der Portico II hervorragend als Stereo-Masterbus-Kompressor. Es ist wunderschön transparent und kann Gewicht, Breite und Dichte hinzufügen. subtile harmonische Sättigung / Körnung; Low-End-Betonung; Mischen/Mastern von „Klebstoff“; Limitierung und mehr auf den Ausgangsbus eines Mixes (oder ggf. einen anderen Track/Bus).
Zusätzlich zur Peak/RMS-Messoption verfügt dieser äußerst vielseitige Kompressor über die Standardsteuerung für Angriff, Auslöse, Schwellenwert, Verhältnis und Make-up-Verstärkung. Es verfügt auch über eine Feedback- / Feed-Forward-Schaltung für einen entspannteren bzw. härteren / schnelleren Kompressionsstil.
Jeder Kanal verfügt außerdem über einen Hochpassfilter, einen Mischknopf für die Parallelverarbeitung und zwei Varianten harmonischer Verzerrung über die übliche Seidenschaltung mit einem speziellen Texturregler. Jeder Kanal kann bei Bedarf auch seitlich verkettet werden.
Schließlich wird Mid-Side-Tweaking mit dem Stereo Field Editor ermöglicht, mit dem Benutzer die Stereoverteilung von Programmmaterial gestalten können. Heben Sie die Seiten mit dem Breitenregler und die Mitten mit dem Tiefenregler hervor. Sowohl die Breiten- als auch die Tiefensteuerung verfügen über eigene Low-, Low-Mid-, High-Mid- oder High-Optionen für eine gezielte Reaktion im Frequenzspektrum.
MeldaProduction MCompressor
Das MeldaProduction MCompressor (Link zum Auschecken in der Plugin Boutique) ist ein fantastisches kostenloses Kompressor-Plugin, das eine Reihe von RMS-Fenstergrößen (von 0 bis 100 ms) sowie eine Spitzenmessung bietet.
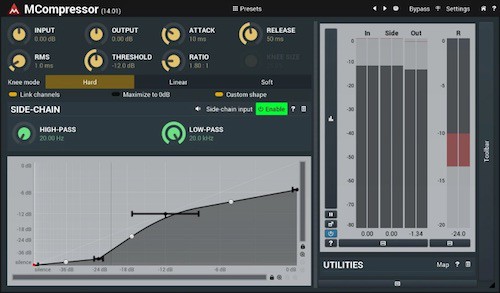
Zusätzlich zu allen zuvor genannten Standardsteuerungen (Attack, Release, Threshold, Ratio, Make-up-Verstärkung) hat der MCompressor auch die Wahl zwischen drei Kniereglern und die Möglichkeit, die Form des Eingangs-/Ausgangsbeziehungsdiagramms / der Kurve des Kompressors anzupassen.
Durch die Gestaltung dieser Kurve können Benutzer den MCompressor effektiv in einen Expander, Gate, „Rhythmizer“, Limiter oder Aufwärtskompressor verwandeln.
Dieses Plugin bietet auch einen Tiefpassfilter zusammen mit einem Hochpassfilter. Darüber hinaus gibt es eine Signalmaximierungsoption, um das maximale Signal auf 0 dB zu bringen.
Dieser Kompressor kann seitlich verkettet werden und kann bis zu 8 Audiokanäle gleichzeitig verarbeiten.
Verwandte Fragen
Sollten Sie zuerst EQ oder komprimieren? Es gibt große Diskussionen darüber, ob ein Equalizer oder ein Kompressor an erster Stelle in der Audiosignalkette stehen sollte. Es gibt keine Regel, die besagt, dass beides zuerst kommen sollte. Im Allgemeinen werden Sie jedoch wahrscheinlich das Beste aus dem EQ und dem Kompressor herausholen, wenn Sie diese Standards befolgen:
- Für die tonale Formgebung ist es oft am besten, vorher zu komprimieren, um zu vermeiden, dass die Kompressoreinstellungen geändert werden müssen.
- Für Audiosignale, die eine signifikante Filterung erfordern, ist es am besten, zuerst EQ zu verwenden, um den Kompressor nicht mit unerwünschten Frequenzinhalten zu versorgen.
Sollte man jeden Track in einem Mix komprimieren? In der Regel sollte die Komprimierung mit Absicht verwendet werden und daher nur auf jeder Spur verwendet werden, wenn jede Spur dies erfordern würde. In den meisten Fällen gibt es bestimmte Spuren in einem Mix, die ohne Dynamikbereichskompression perfekt (und besser) klingen.
Zu den typischen Vorteilen der Komprimierung auf einer Spur gehören (sind aber nicht beschränkt auf) die folgenden:
- Aufrechterhaltung eines konsistenteren Pegels über das gesamte Audiosignal/die gesamte Spur
- Vermeidung von ÜbertreibungOading/Clipping
- Sidechaining von Elementen
- Verbesserung der Nachhaltigkeit
- Verbesserung von Transienten
- Hinzufügen von „Bewegung“ zu einem Signal
- Hinzufügen von Tiefe zu einer Mischung
- Nuancierte Informationen in einem Audiosignal aufdecken
- De-essing
- „Kleben“ einer Mischung (wodurch sie zusammenhängender wird)





